Automated email notifications and task tracking system.
This article explains how to use a Python script in conjunction with a simple Action Tracking spreadsheet to create an automated email notifications and task-tracking system for your team.
To begin, let’s setup our “ActionTracker” spreadsheet as shown below:
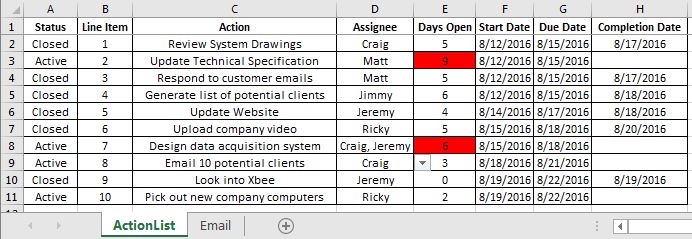
We can use the expression “=IF(ISBLANK(H2)=TRUE,”Active”,”Closed”)” in our Status column to acknowledge when a date has been entered in the “Completion Date” column. This will help our script later on.
The “Days Open” column can be calculated using “=IF(ISBLANK(H2)=FALSE,H2-F2,TODAY()-F2)”. As your list grows, be sure to drag down your formulas.
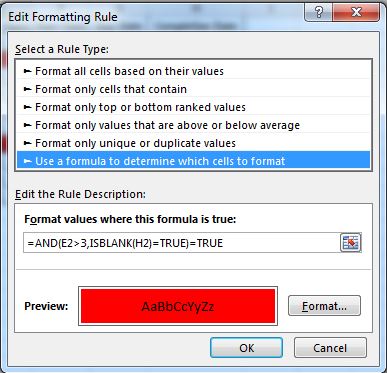
It can be helpful to apply conditional formatting here in order to see which items are “Open” and late, so that we know which items we expect to send notifications about. This can be accomplished by the expression shown below, but it is not a necessary step. Again, remember to update your applicable range as your list grows.
On our “Email” tab, we’ll list our unique assignees by name and add their email addresses (separated by a comma and a space) in column B.

In order to minimize errors, we can apply a Data Validation rule to our “Assignee” column on the “ActionList” tab. We’ll select all of the unique names on our “Email” tab as the Source validation criteria. New emails can easily be added to this list, however, we must update our Source range.

Here’s a download link for the ActionTracker template.
Next, we’ll use the following Python script to send automated email notifications to our team for any Open actions that are open for more than three days. The three day threshold can be easily adjusted in line #50 of the script below.
Note: In order to allow the script to access your gmail account, make sure that your less secure app access settings are currently turned on.
import smtplib
import pandas as pd
import sys
from tkinter import Tk
from tkinter import filedialog
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
#Define email login information.
from_email="_____@gmail.com" #Replace with your email address. Must be gmail.
pw="_____" #Replace with gmail password.
#Select file to use.
Tk().withdraw()
filepath=filedialog.askopenfilename(defaultextension='*.xlsx',
filetypes=[('.xlsx files','*.xlsx'),
('All files','*.*')],
initialdir=r'C:\Users')
if filepath=="." or filepath=="":
sys.exit(0)
#Import ActionTracker
ActionTracker = pd.DataFrame(pd.read_excel(filepath,sheetname='ActionList',
parse_cols='A:E'))
ActionTracker_maxrow=len(ActionTracker)
status=ActionTracker.iloc[:,0]
LineItem=ActionTracker.iloc[:,1]
action=ActionTracker.iloc[:,2]
person=ActionTracker.iloc[:,3]
DaysOpen=ActionTracker.iloc[:,4]
#Import Email Addresses by name
EmailList=pd.DataFrame(pd.read_excel(filepath,sheetname='Email',index_col=0,
parse_cols='A:B'))
#Establish connection to gmail server, login.
server = smtplib.SMTP('smtp.gmail.com',587)
server.starttls()
server.login(from_email, pw)
msg=MIMEMultipart('alternative')
msg.set_charset('utf8')
msg['FROM']=from_email
#Initialize a list of submittals with invalid email addresses
invalid_addresses=[]
#Send emails to late Action Tracker assignees
for i in range(0,ActionTracker_maxrow):
if status[i]=='Active' and DaysOpen[i]>3:
print('Active Line Item #'+str(LineItem[i])+': '+person[i])
msg=MIMEText("Action Tracker Line Item #" + str(LineItem[i]) + " has been open for " +
str(DaysOpen[i]) + " days.\n\n" + str(action[i]) +
"\n\nPlease take action.",_charset="UTF-8")
msg['Subject']="Open Action #" + str(LineItem[i])
msg['TO']=str(EmailList.iloc[EmailList.index.get_loc(person[i]),0])
try:
server.sendmail(from_email, msg['TO'].split(","),
msg.as_string())
except smtplib.SMTPRecipientsRefused:
invalid_addresses.append(LineItem[i])
print('Line Item #' + str(LineItem[i]) + 'has an invalid email address.')
if len(invalid_addresses) != 0:
for i in range(0,len(invalid_addresses)):
invalid_addresses[i]=invalid_addresses[i].strip('\xa0')
try:
if len(invalid_addresses)==1:
msg=MIMEText(str(invalid_addresses) +
" has an invalid email address associated with the responsible party.",
_charset="UTF-8")
else:
msg=MIMEText(str(invalid_addresses) +
" have invalid email addresses associated with the responsible parties.",
_charset="UTF-8")
msg['Subject']='Invalid Email Addresses'
msg['TO']=str(from_email)
server.sendmail(from_email, msg['TO'].split(","),
msg.as_string())
except smtplib.SMTPRecipientsRefused:
print('Invalid Email Address notification email failed.')
server.quit()
And that’s it. Full automation can be achieved by hard-coding in the file location and using Windows Task Scheduler to execute the Python script.